Preventing tables from disappearing after Sandbox Mode
This article discusses the biggest drawback of setting up a BigQuery project in Sandbox mode, before setting up the billing; and how to counteract it to avoid surprises.

This is a Halloween special edition with one of the more prevalent horror stories regarding BigQuery, whereby the following happens:
- company decides to try / use BigQuery (but is afraid of the cost)
- they set up a BigQuery project, but starting it in Sandbox mode (i.e. not setting up billing) to avoid cloud bill surprises
- they set up the GA4 export to BigQuery
- they develop comfort and set up billing by adding their credit card details — thereby switching off Sandbox mode
- few months later, they start analyzing the data: there is a good bit of history available now
- ...
- 💥...😨...😡 the data is not there — only the last two months! (The rest is gone forever.)
What happened?
The implications of using Sandbox Mode
Sandbox mode is great for personal use: you can get accustomed to BigQuery without having to worry about racking up a sizeable bill. (Which btw is a very rare phenomenon: there are only 2-3 tables in the entire BigQuery Public Data collection that weigh some 500TBs, but some lucky people have managed to pick those for trying SELECT * queries. BTW, apparently this person got a full waiver in the end.)
There are some limitations to Sandbox mode:
- you can't do certain SQL things (which, chances are, you won't notice)
- you can't set up a Data Transfer (but you can set up external exports)
- all data will have expiry switched on, with a retention period of maximum 60 days
This last one is the dangerous bit, especially for companies who actually want to analyze that data and retain it for the longer term. Once you set up billing and take the project out of Sandbox mode, you need to make sure to change the retention periods everywhere, as they don't change automatically.
Fixing retention (removing expiration) using the UI
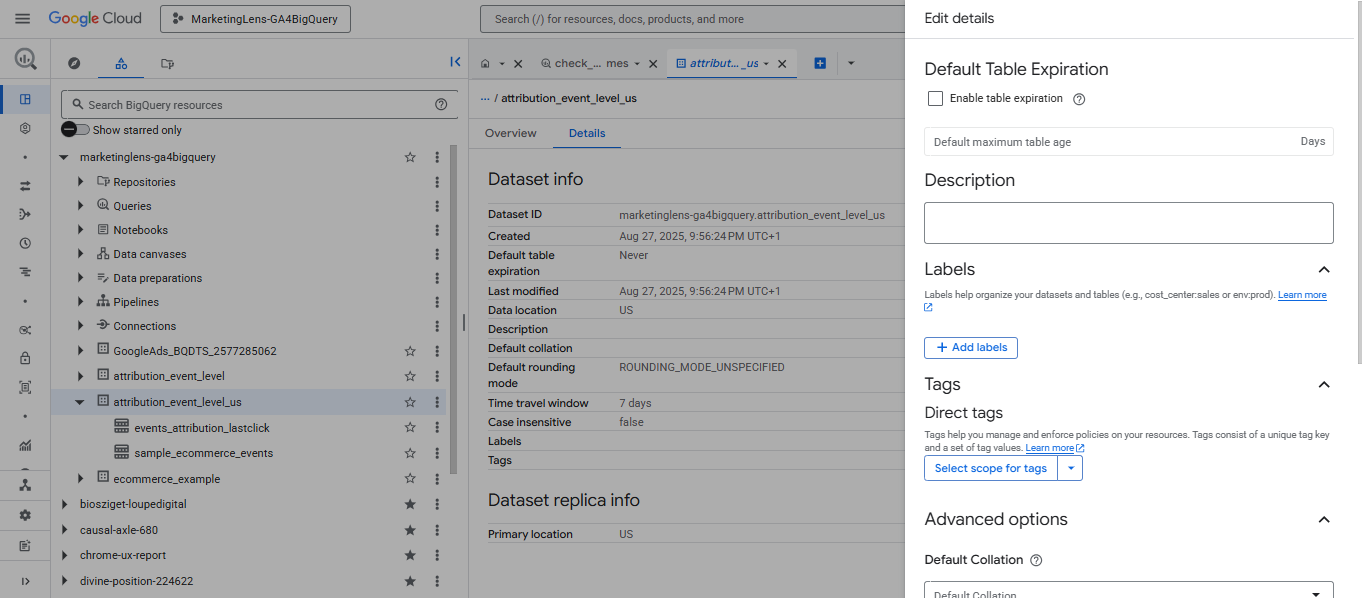
Once the billing is sorted, you need to change the expiration setting on each dataset and each table. Open the dataset from the list, go to the "Details" tab and click the "Edit Details" button (not visible on the screenshot). Upon clicking that button, a new pane / form comes up with the dataset level settings.
You can see the tickbox there: untick that (or change the retention days as appropriate). The setting is called "Default Table Expiration" for a reason: the current setting will apply to any new table in the dataset (i.e. the keyword is "Default").
This means that the tables themselves will STILL expire.
(Unless you address that separately as per the below.)
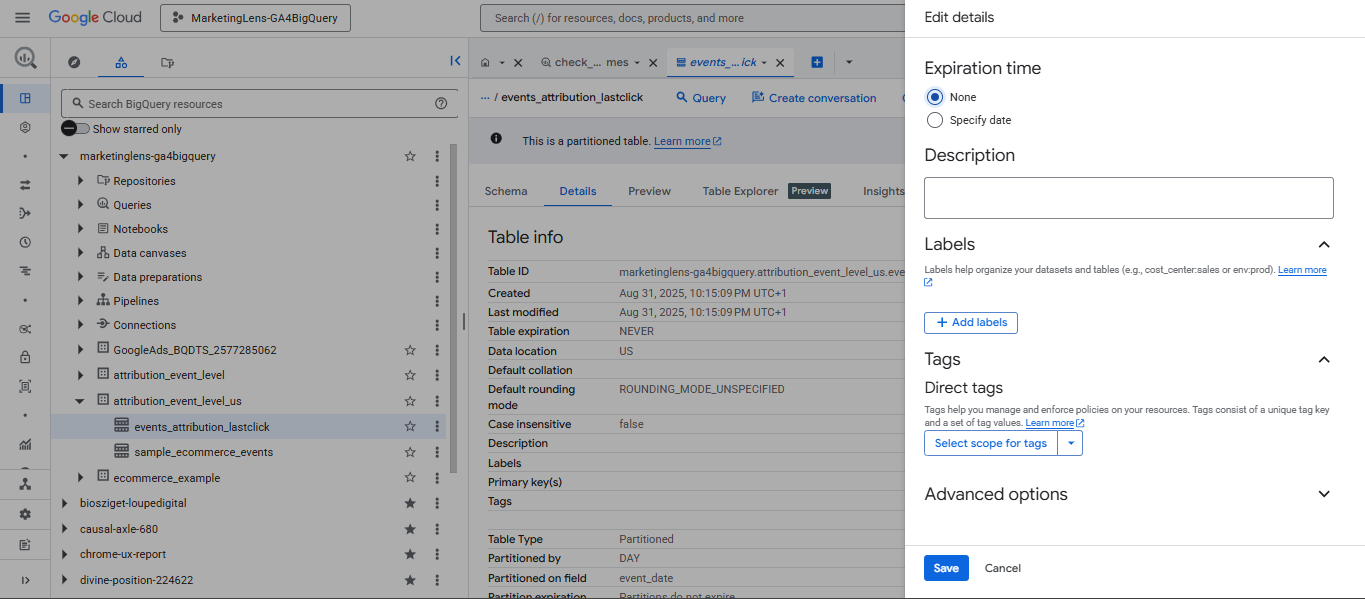
So, we have to click each on our tables, go to the "Details" tab and again click on the "Edit details" button, which will bring up the table details form. Here we have to pick the "None" radio button to save the table from its impending mortality (and we have to click "Save", of course).
Fixing retention programmatically
Of course, all the above is a lot faster with code. Here is how you (un)set the default expiration time on the dataset (which, again, will only apply to new tables):
ALTER SCHEMA your_project_id.your_dataset_name
SET OPTIONS (
default_table_expiration_days = NULL
);. . . or the CLI (Cloud Shell):
bq update --default_table_expiration 0
your_project_id:your_dataset_nameSince the above only fixes the dataset going forward (which still must be done, but is not enough), we have to do it on the individual tables too:
ALTER TABLE your_project_id.your_dataset_name.your_table_name
SET OPTIONS (
expiration_timestamp = NULL
);Or in the CLI:
bq update --expiration 0
your_project_id:your_dataset_name.your_table_nameThe above is still too manual for sharded tables or datasets with many tables. Fortunately, both SQL and Cloud Shell offer FOR loops to do it for multiple tables. We can use the INFORMATION_SCHEMA to look up the tables in question, and apply procedural language to build SQL code that can get directly executed (which is what the EXECUTE IMMEDIATE command was designed for):
DECLARE sql_statement STRING;
FOR tbl IN (
SELECT table_name
FROM `your_project_id.your_dataset_name`.INFORMATION_SCHEMA.TABLES
WHERE table_type = 'BASE TABLE'
)
DO
SET sql_statement = 'ALTER TABLE `your_project_id.your_dataset_name.'||tbl.table_name||'` SET OPTIONS (expiration_timestamp = NULL);';
EXECUTE IMMEDIATE sql_statement;
END FOR;And in the CLI:
#!/bin/bash
PROJECT_ID="$1"
DATASET_ID="$2"
# make sure both arguments are provided
if [ -z "$PROJECT_ID" ] || [ -z "$DATASET_ID" ]; then
echo "Error: Missing arguments; must supply project and dataset."
echo "Usage: $0 <PROJECT_ID> <DATASET_ID>"
exit 1
fi
echo "Starting bulk update for dataset: $PROJECT_ID:$DATASET_ID"
TABLE_LIST=$(bq ls --format=prettyjson --project_id=$PROJECT_ID $DATASET_ID | jq -r '.[] | select(.type == "TABLE") | .>
# Warn if no tables were present in dataset
if [ -z "$TABLE_LIST" ]; then
echo "No tables found in $PROJECT_ID:$DATASET_ID. Exiting."
exit 0
fi
for table in $TABLE_LIST
do
echo "Removing expiration from: $table"
bq update --expiration 0 "$PROJECT_ID:$DATASET_ID.$table" &
done
wait
echo "All table updates complete."Now you can process your tables in bulk. This can also be used to apply retention rules imposed by the data protection officer / committee in your organization, on a mass scale, without putting too much burden on engineering resources.
Closing remarks
This post was inspired by this #MeasureSlack discussion, and the timing of course (this post was written on the day of Halloween, and also at the time of writing this was a fairly recent conversation). Many thanks to Justin Beasley (@justbeez) and Todd Bullivant for sharing their knowledge. All the code in this blog post was written and shared on #MeasureSlack by Justin. Thanks to Elena Osti for starting the discussion.
Now it's your turn!
I hope you've enjoyed this tutorial and feel a bit more confident to manage dataset and table expiration in BigQuery. Drop a line in the comments if you have any questions, feedback or suggestions related to this article.
